
Imagina la escena. Llegas a tu comité gerencial con un business case impecable: ROI proyectado de 3x, esfuerzo estimado en 8 semanas, alineamiento estratégico con la vertical de eficiencia operativa. El caso de uso es un agente de IA que automatiza la resolución de consultas de clientes. Los números cierran. La presentación está limpia. El comité aprueba.
Seis meses después, el proyecto está cancelado.
¿Qué falló? No fue la tecnología. El modelo funcionaba. El equipo técnico cumplió. Lo que falló fue el proceso de evaluación previo: se usaron los mismos criterios que sirven para priorizar una automatización determinística — ROI, esfuerzo, alineamiento — y se asumió que eso era suficiente para un caso de uso de IA.
Adivina: No lo es.
Los datos los demuestran: más del 80% de los proyectos de IA fracasan, el doble que los proyectos de IT tradicional (Fuente: RAND Corporation, 2024). El 74% de las empresas que invierten en IA no logran generar valor tangible (Fuente: BCG, 2024). Y el 42% de las compañías abandonaron la mayoría de sus iniciativas de IA en 2025, más del doble que el año anterior (Fuente: S&P Global, 2025).
La raíz del problema no pasa por los modelos ni en la infraestructura. Está en cómo decidimos qué construir. El proceso de priorización que funciona para automatización determinística — donde la misma entrada siempre produce la misma salida — no considera las dimensiones críticas que un caso de uso de IA necesita para tener éxito en una organización enterprise.
Este artículo propone un proceso completo de evaluación y priorización de casos de uso de IA, diseñado desde la perspectiva de un PM senior que necesita llevar una recomendación sólida a un comité gerencial. Es un framework que integra lo que funciona de la priorización tradicional con las dimensiones nuevas que IA exige.
¿Por qué la priorización de IA es diferente (pero no todo cambia)?
Antes de entrar en el proceso, vale la pena ubicar qué se mantiene y qué cambia. Porque uno de los errores más comunes es tratar la priorización de IA como algo completamente nuevo, descartando años de criterio de producto que siguen siendo válidos.
Lo que se mantiene
La lógica fundamental de producto no cambia con IA. Sigue necesitando:
- Un problema real del usuario. Si no puedes articular qué dolor resuelves y para quién, no importa qué tan sofisticada sea la tecnología.
- Alineamiento con el strategic intent de la organización. ¿El caso de uso mueve alguna de las palancas de valor: aumentar revenue, proteger revenue, reducir costos, evitar costos? Si no conecta con la estrategia, es un experimento interesante pero no una prioridad. He profundizado sobre esto en Strategic Intents: cómo pasar de ejecutar features a resolver lo que realmente importa — el filtro estratégico es el mismo.
- Viabilidad y esfuerzo. Recursos, complejidad, capacidad del equipo.
- Speed to value. Cuánto tarda en generar resultados medibles.
Esa base sigue siendo sólida. El PM que la descarta comete el mismo error que el que la aplica sin ajustar.
Lo que cambia
La inteligencia artificial introduce cuatro cambios fundamentales que la automatización determinística no tiene:
-
Probabilismo. En automatización tradicional, la misma entrada siempre produce la misma salida. Con IA, especialmente IA generativa, los resultados son probabilísticos — pueden variar entre ejecuciones. Esto cambia cómo evalúas riesgo, calidad y auditabilidad.
-
Dependencia de datos como activo estratégico. En automatización tradicional, los datos son inputs fijos y predecibles. En IA, los datos son el activo principal del que depende todo: calidad del modelo, precisión de las respuestas, capacidad de personalización. Si los datos no existen, están sucios o son inaccesibles, el caso de uso es inviable sin importar qué tan buena sea la idea.
-
Degradación silenciosa. Un motor de reglas no se degrada con el tiempo — funciona igual el día 1 que el día 365. Un modelo de IA puede sufrir model drift: su rendimiento se deteriora gradualmente a medida que cambian los datos del mundo real, sin que nadie lo note hasta que el impacto es visible en métricas de negocio.
-
Escrutinio regulatorio y de gobernanza amplificado. Los marcos regulatorios emergentes (EU AI Act, NIST AI RMF, ISO 42001) imponen requisitos de transparencia, explicabilidad y evaluación de impacto que simplemente no existían para la automatización tradicional.
No todo necesita IA
Antes de evaluar cualquier caso de uso, hay una pregunta previa que muchas organizaciones saltan: ¿esto realmente necesita IA?
Pascal Bornet y coautores proponen en Agentic Artificial Intelligence (2025) un framework de cinco niveles que mapea el espectro completo de automatización a autonomía:
| Nivel | Tipo | Qué resuelve | Cuándo es suficiente |
|---|---|---|---|
| 0 | Manual | Nada automatizado | Baseline |
| 1 | Reglas / RPA | Tareas repetitivas con lógica fija | Procesos determinísticos estables |
| 2 | Automatización inteligente | NLP + ML combinados con automatización | Procesos con excepciones manejables |
| 3 | Agentes IA | Razonamiento contextual, multi-paso | Workflows complejos con decisiones |
| 4-5 | Semi/autónomo | Aprendizaje continuo, adaptación | Experimental, con cautela |
El libro complementa esto con el framework SPAR (Sensing, Planning, Acting, Reflecting) como lente diagnóstica: ¿tu caso de uso necesita que el sistema perciba contexto, planifique una estrategia, ejecute acciones y aprenda de los resultados? Si la respuesta es solo “ejecute acciones predefinidas”, probablemente estás en Nivel 1-2 y no necesitas IA.
Un dato que vale la pena tener presente: según BCG (2025), las empresas líderes en IA persiguen la mitad de oportunidades que las rezagadas, pero esperan el doble de ROI por cada una. El foco importa más que la cobertura. El nivel correcto siempre es mejor que el nivel más alto.
Con ese contexto claro, el proceso de evaluación se estructura en cuatro fases secuenciales, cada una con su propio entregable y criterios de avance. Vamos a recorrerlas.
Fase 1 — Discovery: definir el problema antes de la solución
El discovery es la fase donde se identifica y valida el problema del usuario, se mapean los casos de uso candidatos, se estima el valor esperado y se verifica la conexión con el strategic intent de la organización. No es nueva — todo PM senior la conoce. Lo que cambia con IA es lo que necesitas validar dentro de ella.
Lo que se mantiene del discovery tradicional
- Identificar el problema real del usuario, no la solución que alguien ya tiene en mente. “Queremos poner IA en el servicio al cliente” no es un problema — es una solución buscando justificación.
- Validar la conexión con el strategic intent. Si no puedes articular qué palanca estratégica mueve este caso de uso (aumentar revenue, proteger revenue, reducir costos, evitar costos), no avanza. Este filtro no es negociable, con o sin IA.
- Mapear al usuario y su journey actual. ¿Quién es? ¿Qué hace hoy? ¿Dónde está el dolor?
¿Qué cambia con IA en el discovery?
1. Diagnóstico de nivel de autonomía
Antes de comprometerse con un caso de uso, el PM necesita determinar si realmente requiere IA o si se resuelve mejor con reglas determinísticas. Usa el framework de 5 niveles como filtro:
- Si la tarea es repetitiva y la lógica es fija → Nivel 1-2 (reglas, RPA)
- Si requiere interpretar contexto o tomar decisiones con información variable → Nivel 3 (agentes IA)
- Si requiere aprendizaje continuo y adaptación → Nivel 4
En la práctica, muchas empresas saltan directamente a Nivel 3-4 cuando una regla bien diseñada resolvería el 80% del problema a una fracción del costo y con cero riesgo de alucinación.
2. Verificación de viabilidad de datos (go/no-go)
Este es probablemente el cambio más crítico. En automatización tradicional, los datos son inputs fijos — sabes exactamente qué entra y qué sale. En IA, los datos son el activo fundamental del que depende todo.
Aquí no se trata de evaluar la madurez de los datos en detalle (eso viene en Fase 2 con el scorecard). Se trata de responder una pregunta binaria: ¿existe una base de datos razonable para que este caso de uso sea viable, o es un callejón sin salida?
Si la respuesta es “los datos que necesitamos simplemente no existen en ningún sistema” o “no tenemos base legal para acceder a ellos”, el caso de uso muere aquí — sin necesidad de gastar tiempo en las fases siguientes. El 92.7% de los ejecutivos identifican los datos como la barrera más significativa para la implementación de IA, y vale más detectarlo en el discovery que en el mes 3 de desarrollo.
3. Hipótesis de valor, no proyección exacta
En automatización determinística, puedes calcular: “este proceso toma 4 horas manuales, con automatización toma 10 minutos, ahorramos X.” Con IA, esa certeza no existe — la precisión del resultado varía, la adopción es menos predecible, y los costos de monitoreo continuo son reales.
En el discovery, lo que necesitas es una hipótesis de valor creíble que justifique seguir invirtiendo tiempo en evaluación. No un business case cerrado — eso se construye en la Fase 2 cuando tienes todos los scores. Aquí basta con responder: ¿el potencial de impacto es lo suficientemente grande como para justificar el esfuerzo de evaluarlo en detalle?
4. Identificación temprana del output y su impacto en el usuario
¿Qué va a recibir el usuario como resultado de la IA? ¿Una recomendación que puede aceptar o rechazar? ¿Una decisión automatizada que se ejecuta sin su intervención? ¿Un resumen que debe revisar?
Esta definición es crítica porque determina:
- El nivel de riesgo (una recomendación que el usuario puede ignorar vs. una decisión que se ejecuta sola)
- La confianza necesaria (el usuario necesita entender por qué la IA llegó a esa conclusión)
- Las métricas de servicio (cómo vas a medir si el output realmente le sirve al usuario)
Entregable de Fase 1
Una ficha por caso de uso con decisiones binarias — no scores:
| Campo | Pregunta go/no-go |
|---|---|
| Problema del usuario | ¿Hay un dolor identificado y para quién? |
| Strategic intent | ¿Qué palanca estratégica mueve? |
| Nivel de autonomía | ¿Necesita IA o se resuelve con reglas? (Nivel 0-5) |
| Viabilidad de datos | ¿Los datos existen y son accesibles? |
| Hipótesis de valor | ¿El potencial justifica el esfuerzo de evaluación? |
| Output para el usuario | ¿Qué recibe y cómo interactúa con ello? |
Como referencia, Andrew Ng recomienda en su AI Transformation Playbook que el primer piloto no sea necesariamente el caso de uso más valioso, sino el que construya confianza organizacional en un plazo de 6 a 12 meses. Ese criterio aplica especialmente en organizaciones que están empezando su journey con IA.
Fase 2 — Evaluación: el AI Use Case Scorecard
La evaluación es la fase donde los casos de uso que pasaron el discovery se comparan de forma estructurada usando dimensiones que capturan tanto los criterios tradicionales como los específicos de IA. El entregable central es el AI Use Case Scorecard.
Gate de entrada
Solo entran al scorecard los casos que completaron la Fase 1 y pasaron el filtro estratégico. Es decir: tienen un problema validado del usuario, conexión con el strategic intent, y una evaluación preliminar de datos y nivel de autonomía.
Si un caso no puede articular para quién resuelve qué problema, no tiene sentido puntuarlo en las 8 dimensiones — la respuesta ya es clara.
Las 8 dimensiones del Scorecard
Dimensiones que se mantienen (ajustadas para IA)
1. Problem-User Fit (Peso sugerido: 15%)
En Fase 1 validaste que existe un problema real. Aquí la pregunta es otra: ¿qué tan fuerte es la evidencia? No es lo mismo un dolor inferido de una conversación casual que uno validado con datos de comportamiento. Este score permite comparar la solidez del fundamento entre casos que ya pasaron el filtro.
| Score | Descripción |
|---|---|
| 5 | Problema validado con datos de usuario, demanda clara |
| 4 | Problema identificado con evidencia indirecta |
| 3 | Problema inferido de feedback cualitativo |
| 2 | Evidencia débil, requiere más discovery |
| 1 | Fundamento insuficiente para este nivel de inversión |
2. Business Impact (Peso sugerido: 15%)
Impacto en revenue, costos o eficiencia. En Fase 1 validaste que la hipótesis de valor justifica seguir. Aquí se construye el caso financiero real, con tres escenarios — conservador (40% del beneficio), moderado (70%), optimista (100%) — porque la naturaleza probabilística de IA hace que un ROI puntual sea engañoso.
| Score | Descripción |
|---|---|
| 5 | Impacto alto en escenario conservador |
| 4 | Impacto alto en escenario moderado |
| 3 | Impacto moderado en escenario moderado |
| 2 | Impacto bajo o solo en escenario optimista |
| 1 | Impacto marginal o no cuantificable |
3. Speed to Value (Peso sugerido: 10%)
Tiempo a resultados medibles. Se recalibra para IA: el promedio de prototipo a producción es de 8 meses según Gartner — significativamente más que una automatización determinística.
| Score | Descripción |
|---|---|
| 5 | Resultados medibles en menos de 3 meses |
| 4 | Resultados en 3-6 meses |
| 3 | Resultados en 6-9 meses |
| 2 | Resultados en 9-12 meses |
| 1 | Más de 12 meses o timeline incierto |
Dimensiones que evolucionan
4. Feasibility & Effort (Peso sugerido: 10%)
Complejidad técnica, recursos necesarios y capacidad del equipo. Con IA, ahora incluye:
- Skill gap: ¿tenemos talento de ML/IA internamente o necesitamos contratación o partners?
- Complejidad de integración: ¿cuántos sistemas se necesitan conectar?
| Score | Descripción |
|---|---|
| 5 | Equipo capacitado, integración simple, recursos disponibles |
| 4 | Skill gap menor, integración moderada |
| 3 | Necesita formación o contratación puntual |
| 2 | Skill gap significativo, integración compleja |
| 1 | Requiere capacidades que no existen en la organización |
5. Viabilidad técnica / Arquitectura empresarial (Peso sugerido: 10%)
¿Cómo se conecta la solución con la arquitectura empresarial existente? En automatización tradicional, la integración es predecible — conectas APIs conocidas con flujos determinísticos. Con IA, necesitas evaluar dimensiones que antes no existían:
- ¿Dónde corre el modelo? On-premise, cloud, API externa (OpenAI, Anthropic, etc.)
- ¿Cómo se integra con los sistemas core? ERP, CRM, data warehouse, plataformas de atención
- ¿La infraestructura soporta los requisitos? Latencia, capacidad de cómputo, almacenamiento de embeddings
- ¿Es compatible con el stack de producción? Monitoreo, logging, CI/CD existente
| Score | Descripción |
|---|---|
| 5 | Se integra nativamente con la arquitectura actual |
| 4 | Requiere adaptaciones menores |
| 3 | Requiere componentes nuevos pero compatibles |
| 2 | Requiere cambios significativos en infraestructura |
| 1 | Incompatible con la arquitectura actual |
Dimensiones nuevas de IA
6. Data Readiness (Peso sugerido: 15%)
En Fase 1 verificaste que los datos existen y son accesibles (go/no-go). Aquí la pregunta es cuánto trabajo falta para que estén listos para producción. Eso determina esfuerzo real, timeline y riesgo de ejecución. Se descompone en tres sub-criterios:
- Disponibilidad: ¿están consolidados o fragmentados entre sistemas?
- Calidad: ¿requieren limpieza menor o un proyecto de data engineering?
- Acceso: ¿los pipelines de acceso ya existen o hay que construirlos?
| Score | Descripción |
|---|---|
| 5 | Datos limpios, accesibles y con base legal clara |
| 4 | Datos disponibles con limpieza menor necesaria |
| 3 | Datos existen pero requieren trabajo significativo |
| 2 | Datos parciales o fragmentados entre sistemas |
| 1 | Datos no existen o son inaccesibles |
7. Error Tolerance & Human-in-the-Loop (Peso sugerido: 15%)
La tolerancia al error es la dimensión que más diferencia la evaluación de IA de la automatización tradicional. En un sistema determinístico, si funciona correctamente, funciona siempre. En IA, los errores son inherentes al sistema.
Dos conceptos clave:
- Sev-0: el error que el usuario no puede detectar — es el más peligroso. Ejemplo: la IA le da información incorrecta al cliente y el cliente la toma como verdadera.
- Sev-1: el error que el usuario detecta pero no puede recuperar fácilmente. Ejemplo: una decisión automatizada que requiere un proceso de apelación.
Los datos son reveladores: la tasa de alucinación sin mitigación en modelos de lenguaje es del 15-20% (Fuente: Elementum AI). Y el error se compone: tres pasos encadenados con 90% de precisión cada uno resultan en solo 73% de precisión total. Cada eslabón en la cadena multiplica el riesgo.
| Score | Descripción |
|---|---|
| 5 | Alta tolerancia, errores detectables y recuperables |
| 4 | Tolerancia moderada con mecanismo de revisión |
| 3 | Requiere human-in-the-loop para decisiones críticas |
| 2 | Baja tolerancia, errores costosos de revertir |
| 1 | Cero tolerancia, errores pueden ser catastróficos |
8. Governance & Compliance (Peso sugerido: 10%)
Esta dimensión clasifica el nivel de escrutinio que el caso de uso va a requerir — no lo ejecuta. Es una estimación que anticipa cuánto esfuerzo demandará la Fase 3 (validación con áreas de control). Un caso que puntúa 1-2 aquí no es necesariamente inviable, pero el PM debe saber que la validación va a ser larga, costosa, y podría cambiar los términos del proyecto.
| Score | Descripción |
|---|---|
| 5 | Bajo riesgo regulatorio, pre-aprobable |
| 4 | Riesgo estándar, review normal |
| 3 | Requiere evaluación de impacto formal |
| 2 | Alto riesgo, requiere oversight humano continuo |
| 1 | Posible prohibición regulatoria o riesgo reputacional extremo |
Ejemplo comparativo: 3 casos evaluados
Para hacer tangible el scorecard, evaluemos tres casos de uso tipo en una empresa de servicios financieros:
| Dimensión | Caso A: Conciliación | Caso B: Agente atención | Caso C: Scoring IA |
|---|---|---|---|
| Problem-User Fit | 4 | 4 | 5 |
| Business Impact | 3 | 4 | 5 |
| Speed to Value | 5 | 3 | 3 |
| Feasibility & Effort | 5 | 3 | 3 |
| Arquitectura | 4 | 3 | 4 |
| Data Readiness | 5 | 3 | 4 |
| Error Tolerance | 5 | 2 | 3 |
| Governance | 5 | 3 | 2 |
| Score ponderado | 4.4 | 3.1 | 3.6 |
Caso A: Automatización de conciliación financiera (Nivel 1-2). Score alto porque es un caso de automatización determinística con reglas claras. Paradójicamente, el caso que más puntúa no necesita IA — y eso está bien. El scorecard no asume que IA es siempre la respuesta.
Caso B: Agente de atención al cliente (Nivel 3). Score medio-alto en impacto pero bajo en tolerancia al error y governance. El agente puede dar información incorrecta a clientes (Sev-0) y opera en un dominio con regulación financiera. Necesita human-in-the-loop robusto, lo que aumenta costo y complejidad.
Caso C: Scoring crediticio alternativo con IA (Nivel 2-3). El mayor business impact potencial, pero governance es desafiante — decisiones de crédito tienen regulación estricta sobre explicabilidad y no discriminación. Data readiness es favorable porque las transacciones ya existen en los sistemas.
La lectura del scorecard no es solo “el número más alto gana”. Es una conversación sobre dónde están los riesgos y si tienes plan para mitigarlos.
Fase 3 — Validación con áreas de control
La validación es la fase donde los casos priorizados pasan por la revisión formal de las áreas de riesgos, seguridad, auditoría, gobierno corporativo y legal. Es el paso que convierte una evaluación de producto en una evaluación enterprise.
En toda organización enterprise, este paso existe para cualquier proyecto relevante — no es nuevo. Lo que cambia radicalmente con IA es el contenido de la conversación con cada área.
¿Qué cambia con IA en cada área de control?
Riesgos
La IA introduce riesgos que no existen en automatización determinística: bias algorítmico, alucinaciones, decisiones opacas ejecutándose a escala, model drift silencioso. El equipo de riesgos necesita entender algo fundamental: que el modelo pueda dar respuestas diferentes para el mismo input no es un bug — es la naturaleza del sistema. La conversación no es “¿cómo eliminamos la variabilidad?” sino “¿cómo la acotamos a niveles aceptables?”
Seguridad
La superficie de ataque se amplía con IA. Vectores que antes no existían:
- Prompt injection: manipular al modelo para que ignore sus instrucciones
- Data poisoning: contaminar los datos de entrenamiento
- Exfiltración: extraer datos sensibles que el modelo memorizó durante el entrenamiento
La revisión de seguridad ahora incluye amenazas que los frameworks tradicionales de ciberseguridad no contemplaban.
Auditoría
En automatización determinística, la trazabilidad es simple: misma entrada produce misma salida, puedes reconstruir cualquier decisión. Con IA, necesitas un nivel de logging mucho más granular: inputs, outputs, versión del modelo, score de confianza, y decisiones de fallback a humano. Los estándares de auditoría (SOC 2, GDPR, SOX) asumen que los sistemas producen resultados predecibles y reproducibles — la IA desafía esa asunción fundamentalmente.
Gobierno corporativo
La pregunta más incómoda: ¿quién es responsable cuando la IA se equivoca? La respuesta no puede ser “el modelo” — tiene que ser una persona con accountability clara. En la práctica, es el PM del producto. Solo 1 de cada 5 empresas tiene un modelo de governance maduro para IA (Fuente: Deloitte, 2025).
Legal
Las regulaciones emergentes requieren clasificación de riesgo del sistema, evaluación de impacto y transparencia. El EU AI Act, que ya está vigente, contempla multas de hasta EUR 35 millones o el 7% del revenue anual global para prácticas prohibidas. No es un riesgo teórico — es regulación operativa.
Entregable de Fase 3
Una ficha de validación por caso de uso:
| Campo | Contenido |
|---|---|
| Riesgos identificados | Lista de riesgos específicos de IA |
| Mitigaciones propuestas | Plan concreto por riesgo |
| Tier de gobernanza | Pre-aprobado / Review estándar / Aprobación completa |
| Compliance requerido | Frameworks aplicables y estado |
| Aprobaciones necesarias | Qué áreas deben firmar y cuándo |
El mensaje clave: en automatización tradicional, la validación con áreas de control es frecuentemente un trámite de bajo esfuerzo. Con IA, es una fase sustantiva que puede cambiar el tier del proyecto, agregar requerimientos de human-in-the-loop que no estaban previstos, aumentar costos operativos, o incluso descalificar un caso de uso que parecía viable en el scorecard. Planificar esta fase desde el inicio — no dejarla para el final — es lo que separa a los equipos que llegan al comité con una propuesta sólida de los que llegan con sorpresas.
Métricas de éxito — el modelo de cuatro capas
Antes de la presentación al comité, el PM necesita definir cómo va a medir el éxito del caso de uso. Y aquí está uno de los errores más frecuentes: definir solo métricas de negocio (revenue, reducción de costos) y descubrir a los 6 meses que no tienes visibilidad de por qué no se están cumpliendo.
Las métricas de negocio son el resultado final, no la señal temprana. Entre la implementación de IA y el impacto en el negocio hay tres capas intermedias que el PM necesita monitorear para poder diagnosticar, ajustar y aprender.
La cadena causal de métricas
Capa 1 → Capa 2 → Capa 3 → Capa 4. Si una capa falla, las siguientes no se activan.
Capa 1: Métricas técnicas (¿la IA funciona?)
- Precisión del modelo, tasa de alucinación, latencia de respuesta, uptime, tasa de fallback a humano
- Son la base. Si el sistema no responde correctamente o se cae, nada más importa.
- Cuándo se miden: semanas 1-2 post-deployment.
Capa 2: Métricas de servicio (¿el usuario percibe valor real del output?)
- Satisfacción con el resultado específico, resolución efectiva del problema, calidad percibida del output, tasa de rechazo o corrección manual del resultado
Esta capa es la que muchos equipos saltan — y es la que explica la mayoría de los fracasos silenciosos.
Un ejemplo concreto: un recomendador de productos puede tener 95% de precisión técnica (Capa 1 saludable). El modelo identifica correctamente patrones de compra y sugiere productos “relevantes” según su algoritmo. Pero si esos productos terminan siendo devueltos porque el usuario no los necesitaba realmente — solo encajaban en un patrón estadístico —, la métrica de servicio revela que el modelo está optimizando para lo incorrecto. La IA “funciona” técnicamente pero no le sirve al usuario.
La diferencia entre la Capa 1 y la Capa 2 es la diferencia entre “el sistema hace lo que se diseñó para hacer” y “lo que hace le genera valor real al usuario”. No siempre coinciden.
- Cuándo se miden: semanas 3-4 post-deployment.
Capa 3: Métricas de producto (¿el usuario adopta y vuelve?)
- Tasa de adopción, engagement (frecuencia de uso), retención, NPS/CSAT del feature
- Si el servicio entrega valor real (Capa 2 saludable) pero el usuario no adopta, el problema no es técnico ni de calidad del output — es de product-market fit, diseño del flujo o propuesta de valor. Es decir, el output es bueno pero el producto no logra que el usuario lo descubra, lo entienda o lo integre en su rutina.
- Cuándo se miden: meses 2-3 post-deployment.
Capa 4: Métricas de negocio (¿genera el impacto esperado?)
- Revenue impact, reducción de costos, EBIT, tiempo de ciclo, conversion rate
- Son el resultado de que las capas 1-3 funcionen. Son las que validan que el caso de uso cumple con el strategic intent de la organización.
- Cuándo se miden: meses 4-6 post-deployment.
Las 4 capas en cada caso de uso
| Capa | Conciliación (Nivel 1-2) | Agente atención (Nivel 3) | Scoring IA (Nivel 2-3) |
|---|---|---|---|
| Técnica | Tasa de match automático, errores de parsing | Precisión de respuestas, latencia, tasa de hallucination | Precisión del score, tasa de falsos positivos |
| Servicio | Satisfacción del analista con excepciones resueltas | Resolución real del problema del cliente, no solo “respuesta dada” | Score percibido como justo por el usuario, tasa de apelación |
| Producto | Adopción del equipo, frecuencia de uso vs. proceso manual | Tasa de usuarios que eligen el agente vs. canal humano | Tasa de aceptación de ofertas basadas en el score |
| Negocio | Horas ahorradas en conciliación, reducción de errores | Costo por resolución, CSAT general, deflection rate | Tasa de aprobación, morosidad, revenue incremental |
El comité necesita ver la Capa 4. Pero el PM necesita operar las 4. Si solo reportas métricas de negocio, pierdes la capacidad de diagnosticar y ajustar a tiempo. Si solo reportas métricas técnicas, pierdes visibilidad de si el usuario realmente está recibiendo valor.
La ventaja del modelo de 4 capas: cuando la Capa 4 no se cumple, puedes rastrear la cadena hacia atrás y diagnosticar exactamente en qué capa se rompió. ¿La IA funciona pero el usuario no percibe valor? Problema de Capa 2 — revisa qué está optimizando el modelo. ¿El usuario percibe valor pero no adopta? Problema de Capa 3 — revisa el flujo y la propuesta de valor.
Fase 4 — Presentación al comité: el entregable
La presentación al comité gerencial es donde las fases anteriores se consolidan en un entregable ejecutivo. No es un documento nuevo — es la síntesis de todo lo evaluado, diseñada para que el comité pueda tomar una decisión informada.
Estructura de la presentación
1. Executive summary
El problema del usuario que se resuelve, el strategic intent que aborda, la solución propuesta y el nivel de autonomía recomendado. En una página. Si no puedes explicar por qué este caso importa en una página, la propuesta no está lista.
2. Scorecard comparativo
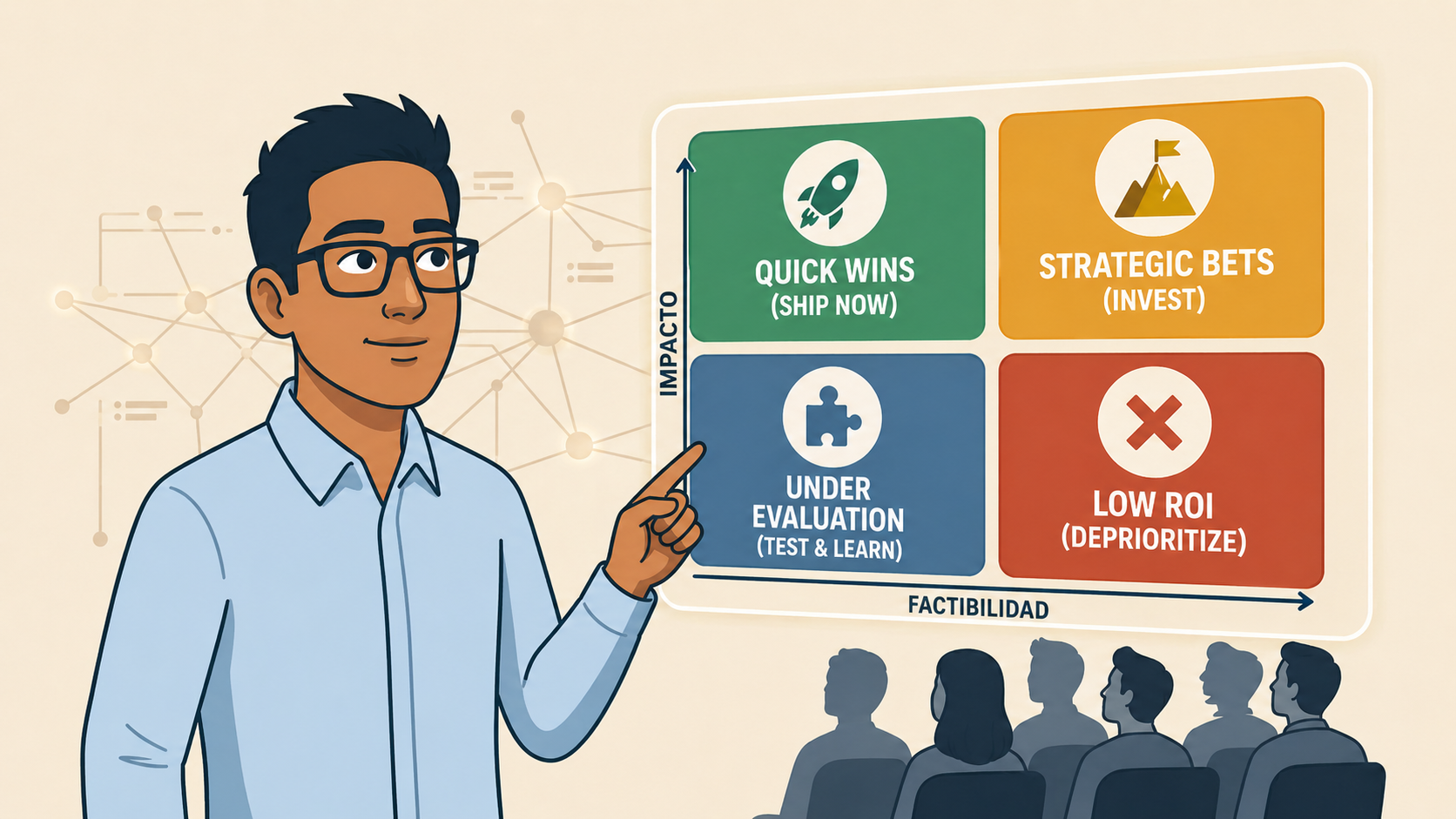
Los 3-5 casos evaluados, lado a lado, con sus scores por dimensión. Presentado de forma visual — una tabla o un quadrant plot de impacto vs. viabilidad. El comité no va a leer 8 fichas detalladas — necesita ver la comparación de un vistazo.
3. Validación de control
Tier de gobernanza asignado a cada caso, riesgos principales identificados y mitigaciones propuestas. El comité necesita saber que las áreas de control ya revisaron esto — no quiere sorpresas después de la aprobación.
4. Tres escenarios financieros
Por caso priorizado: conservador (40% del beneficio proyectado), moderado (70%), optimista (100%). Incluir la inversión requerida y el breakeven en cada escenario. El comité evalúa con el escenario conservador — si los números no cierran ahí, el caso necesita más trabajo.
5. Dashboard de métricas de éxito en 4 capas
Técnica → Servicio → Producto → Negocio. Las métricas específicas de cada capa para el caso recomendado. Esto demuestra que no solo estás midiendo el resultado final sino que tienes un plan para diagnosticar y ajustar en el camino.
6. Plan de iteración
Qué se mide en cada ventana temporal:
- Semanas 1-2: métricas técnicas (¿funciona?)
- Semanas 3-4: métricas de servicio (¿le sirve al usuario?)
- Meses 2-3: métricas de producto (¿adopta?)
- Meses 4-6: métricas de negocio (¿genera impacto?)
Con decision points de go/no-go claros: ¿qué tiene que pasar en cada ventana para seguir invirtiendo?
7. Recomendación
Cuál caso priorizar primero y por qué. La recomendación no es siempre el caso con mayor score — puede ser el que construye confianza organizacional, el que tiene menor riesgo de ejecución, o el que genera aprendizajes que habilitan los casos siguientes.
Lo que el C-level necesita ver vs. lo que el PM necesita operar
| C-level | PM |
|---|---|
| Executive summary + scorecard | Fichas detalladas de discovery y evaluación |
| Escenarios financieros | Modelo de 4 capas completo |
| Tier de gobernanza | Fichas de validación de control |
| Métricas de negocio (Capa 4) | Las 4 capas + decision points |
| Recomendación | Plan de iteración con ajustes |
El comité aprueba o rechaza. El PM opera el detalle. El puente entre ambos es la presentación — y su calidad determina si un caso de uso bien evaluado se aprueba o se pierde en la discusión.
Un dato que refuerza esto: según McKinsey (2025), el 55% de las empresas que logran alto impacto con IA rediseñaron sus procesos fundamentalmente antes de implementar la tecnología — casi 3 veces más que el resto. Y BCG lo cuantifica con su regla 10/20/70: el 10% del esfuerzo es algoritmos, el 20% es tecnología y datos, y el 70% es personas y procesos. El entregable al comité no es un trámite — es la manifestación de que hiciste el 70% del trabajo que realmente importa.
El proceso completo: de discovery a comité
Para cerrar con una vista consolidada, el proceso completo se ve así:
| Fase | Pregunta central | Entregable | ¿Qué puede matar el caso? |
|---|---|---|---|
| 1. Discovery | ¿Resolvemos un problema real del usuario que conecta con el strategic intent? | Ficha de caso de uso | No hay problema validado, datos inexistentes, nivel de autonomía equivocado |
| 2. Evaluación | ¿Cómo puntúa en las 8 dimensiones vs. otros casos? | AI Use Case Scorecard | Score bajo en dimensiones críticas sin plan de mitigación |
| 3. Validación | ¿Las áreas de control aprueban el tier de riesgo? | Ficha de validación | Riesgo regulatorio inaceptable, governance inmaduro, seguridad comprometida |
| 4. Comité | ¿El caso justifica la inversión con un plan claro de métricas? | Presentación ejecutiva | Escenario conservador no cierra, sin plan de iteración creíble |
Cada fase es un filtro. No todo caso de uso que entra al discovery llega al comité — y eso está bien. Es preferible descalificar un caso en la Fase 1 que cancelarlo en el mes 6 de implementación.
Reflexión final
El PM que prioriza IA en una organización enterprise no necesita ser experto en modelos de lenguaje ni entender los detalles de fine-tuning. Necesita algo más difícil: ser brutalmente honesto sobre qué sabe y qué no sabe su organización — y tener la disciplina de evaluar en fases y medir en capas.
En un mercado donde el 97% de las empresas desplegaron agentes de IA en el último año pero solo el 29% ve retorno significativo (Fuente: Writer, 2026), la ventaja competitiva no está en la velocidad de adopción. Está en la calidad del proceso previo: un discovery que no se salta el problema del usuario, una evaluación que captura las dimensiones que la automatización tradicional ignora, una validación que anticipa los riesgos en vez de descubrirlos en producción, y métricas que permiten aprender y ajustar en vez de solo reportar si funcionó o no.
Antes de tu próximo business case de IA, te invito a llevar cada caso por las cuatro fases. Si el discovery no articula un problema real del usuario, no avances al scorecard. Si el scorecard tiene dimensiones en 1-2 sin plan de mitigación, esa es la conversación que tu comité debería tener primero. Y si defines métricas, asegúrate de que no sean solo de negocio — las capas intermedias son las que te van a dar la señal para ajustar a tiempo.
La IA no cambia lo fundamental del rol de producto. Cambia la profundidad y la honestidad con la que necesitas evaluar antes de construir.
Fuentes y referencias
- BCG — From Potential to Profit: Closing the AI Impact Gap (2024). Boston Consulting Group. bcg.com
- BCG — AI Radar 2025: Leading in the Age of AI (2025). Boston Consulting Group. bcg.com
- Bornet, Pascal et al. — Agentic Artificial Intelligence (2025). Springer.
- Deloitte — State of AI in the Enterprise (2025). Deloitte Insights. deloitte.com
- Elementum AI — Understanding LLM Hallucination Rates. elementum.ai
- EU AI Act — Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence. Parlamento Europeo y Consejo de la UE. artificialintelligenceact.eu
- Gartner — Moving AI From Prototype to Production. gartner.com
- McKinsey — The State of AI: How organizations are rewiring to capture value (2025). McKinsey Global Institute. mckinsey.com
- Ng, Andrew — AI Transformation Playbook. Landing AI. landing.ai
- RAND Corporation — Identifying and Mitigating the Risks of AI (2024). rand.org
- S&P Global — AI and Enterprise Technology Survey (2025). spglobal.com
- Writer — State of AI in the Enterprise (2026). writer.com